RLP编码¶
在 Merkle Patricia树 的结尾,我们提到了 RLP 编码,我们来看下它究竟是什么。
RLP 编码全称 Recursive Length Prefix 编码方法,是一种递归性质的编码方式。
从RLP编码的英文名称中我们可以看出,该编码方式的特色就是可以用同一个编码函数递归地正向编码,直到不能再编码为止。 同样的过程也适用于解码,仅需将解码成果向同一个解码函数代入,直到彻底变为明文为止。
那么,为何RLP编码被广泛地使用在了以太坊的数据存储及数据传输的过程中呢?经过考察之后,我们认为该算法有如下的几个特点。
- 编码/解码逻辑足够简单。
- 应用在底层字节类型 Byte 层面上,节约占用空间。
- 可以采用流式方式解码,提高网络传输效率。
在计算机空间中,数据往往按照字节存储,RLP编码应用在字节类型(Byte)数据上正是瞄准了最底层的存储空间。该算法定义可编码的 数据项 如下所示。
- 一条基本的字符串(即为byte数组)。
- 一个数组,每个数组元素为一个 数据项 ,可以是空数组。
具体举例来说,RLP进行底层编码的通常形式的“数据项”是如下形式的。
“Buenas”[][“cat”, “dog”][“What”, [“is”, “your”], [], “name”, [[“?”]]]
RLP编码是没有办法针对字典类型的数据进行编码的,
例如形如 {“a”:1, “b”:2} 这样的字典结构是需要更高阶的编码方式编码后,再交给RLP进行底层编码。
同样的,各种中文字符或特殊符号也是需要更高阶的函数将其编码为Byte数组以后再交到RLP进行底层编码。
RLP编码的 数据项 分为两种:字符/字符串和数组。
RLP字符/字符串编码¶
我们首先来讲一下针对字符和字符串的具体编码方式。首先回顾一下ASCII字符对照表。
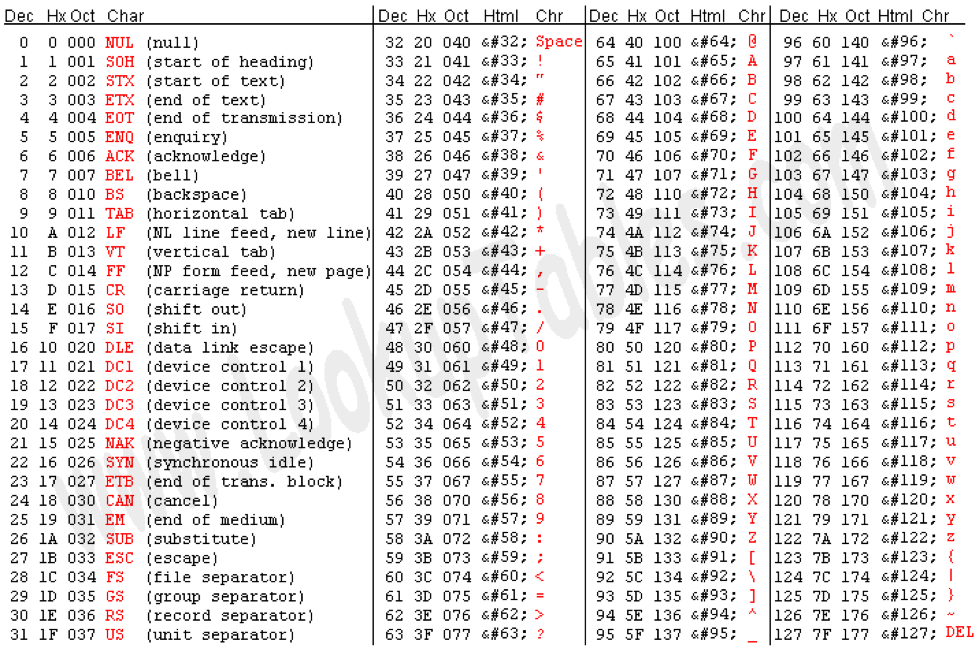
ASCII字符对照表
ASCII表涵盖了0~127个字符,按照16进制表达就是 0x00 ~ 0x7f 。
一个Byte能够覆盖的范围是0~255, 0x00 ~ 0xff 。
若单一字符在
0x00~0x7f范围内,则保持原样,不作变更。- 0x78 => 0x78
若单一字符在
0x80~0xff范围内,则前缀0x81。- 0xef =>
0x81, 0xef
- 0xef =>
若不是单一字符,为 2~55 个字符组成的字符串,则前缀“
0x80+ 字符串长度”,并紧接着书写字符串的 16 进制表达,所以开头字节范围为0x82~0xb7。分步骤如下
- “hello” = h, e, l, l, o = 0x68, 0x65, 0x6c, 0x6c, 0x6f
- “hello” 长度为5,与前缀 0x80相加
0x80+ 0x05 =0x85 - 整合编码后得出结果:
0x85, 0x68, 0x65, 0x6c, 0x6c, 0x6f
若为 55 个以上字符组成的字符串,RLP编码分为三个部分,从 右往左 依次为:原始字符串的16进制表达 P1 ,字符串总长度的16进制表达 P2 ,0xb7和 P2 长度的加和值 P3 ,P3 的范围在
0xb8~0xbf。分步骤如下
- “aaaa….aaaa”共 2000 个字符 = 0x61, 0x61 …. 0x61 (共2000个字节) 这是 P1
- 字符串总长度 2000 个字节,2000 转为 16 进制后表达为 07d0 =
0x07, 0xd0(共2个字节) ,这是 P2 - 由于上述长度表达式占用 2 个字节,最前端前缀为0xb7 + 2 =
0xb9, 这是 P3 - 依序排列 P3, P2, P1 :
0xb9,0x07, 0xd0, 0x61, 0x61,…, 0x61
RLP字符/字符串解码¶
对于最基本的字符/字符串变量,RLP编码的解码过程将同样直观且顺利, 当解码器遇上一个字符时,仅需判断其范围即可决定紧接着的字符应该采用何种方式进行解码。 可以说是一个相当好用的流式解码。
| 字符串开头 | 代表的含义 |
| 0x00~0x7f | 按照ASCII直接翻译该字符 |
| 0x81 | 会紧跟一个特殊的字符 |
| 0x82~0xb7 | 会紧跟一条不大于55个的字符串 |
| 0xb8~0xbf | 会紧跟一条大于55个的字符串 |
例如我们上文的 0xb9 , 0x07, 0xd0 , 0x61, 0x61,…, 0x61 字符串,我们拿到以后对照上表
0xb9提示这是一个功能性字符,它后方会紧跟一个大于 55 个长度的字符串。 字符串长度多少?表达长度的区域将会占用 0xb9 - 0xb7 = 2 个字符。- 顺序读取接下来两个字符
0x07, 0xd0 - 这两个字符拼合
07d0代表16进制的 2000,提示我们后方是一个2000个字符串。 - 顺序读取接下来的2000个字符。
- 发现都是 0x61, 按照 ASCII直接翻译该字符即可。为
"a"
RLP数组编码¶
我们看到字符串的编码范围用到了 0xbf 就到了顶峰,再向上起始范围是 0xc0 ,这个就是数组的编码起始范围。针对数组,RLP编码定义如下所示。
空数组编码为
0xc0[]=>0xc0
每个数组项必须事先分别经过RLP编码。
如果各项数组项的RLP编码结果总和数据在1~55个字符长度内,则前缀
0xc0+ 数据总长,再串联数据形成最终结果,前缀范围是0xc1~0xf7。分步骤拆解入下
- 各自RLP编码:[“hello” “world”] = RLP( RLP(“hello”), RLP(“world”) )
- RLP(“hello”) = [0x85, 0x68, 0x65, 0x6c, 0x6c, 0x6f] (长度为6)
- RLP(“world”) = [0x85, 0x77, 0x6f, 0x72, 0x6c, 0x64] (长度为6)
- 总数据长度 6 + 6 = 12 = 0x0c
- 前缀值
0xc0+ 0x0c =0xcc - 总编码结果为:[
0xcc,0x85, 0x68, 0x65, 0x6c, 0x6c, 0x6f,0x85, 0x77, 0x6f, 0x72, 0x6c, 0x64]
- 如果各数据项的RLP编码结果综合数据在 55 个字符以上,则按照三部分安排,
从 右往左 依次是:各数据项分别经过RLP编码后的结果 P1 , 总数据体量的 16 进制表达 P2 ,
0xf7+ 数据体量的长度前缀 P3 ,P3的范围在0xf8~0xff。
RLP数组解码¶
略
RLP算法已经明明白白地安排了从 0x00~0xff 每个字符的含义,并且巧妙地使用了 0x80, 0x81, 0xc0 作为分隔符将这些范围划分为数个空间, 在解码时,根据开头就能判断接下去来的数据类型。我们将上面解码表格补充完整,加入对字符串的解码规则。
| 字符串开头 | 代表的含义 |
| 0x00~0x7f | 按照ASCII直接翻译该字符 |
| 0x81 | 会紧跟着一个特殊的字符 |
| 0x82~0xb7 | 会紧跟一条不大于55个的字符串 |
| 0xb8~0xbf | 会紧跟一条大于55个的字符串 |
| 0xc1~0xf7 | 会紧跟一个不大于55个字符的数组 |
| 0xf8~0xff | 会紧跟一条大于55个字符的数组 |