Radix树¶
树(Trie) 是计算机科学领域的专有名词 [1] ,有时候也是用 Tree 来替代,这两者基本是同义词。
换句话说,树是有组织的数据结构,用来存储经常动态变化的数据,单条数据是一个键值对(key-value pairs),键的构成是一个字符串,见图 4-1
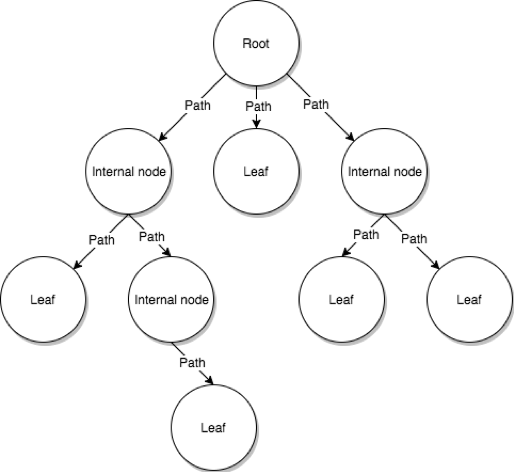
树由树根,树内节点与叶子节点组成
树的结构中常见的名词解释如下。
node节点:用圆圈表示,节点包含键、值、与指向后继节点的路径。root树根:树的起始节点,一棵树有且仅有一个树根。leaf树叶:树的最下层末梢节点,再无后继节点。internal node内部节点: 树中间的节点,承上启下,在上层与后继都有节点。Path路径:连结两个节点之间的直线,可以是双向箭头,也可以是单向箭头。
最常见的树结构就是 二叉树 ,每个节点最多两个后继节点,称为左右“孩子”。 从上往下层层遍历可以快速找到需要的值,一般在 N 个值中查找的复杂度在 log2(N) 范围内,相比于列表的 N 线性查找速度快很多。 二叉树有很多变种,其中有名的 MySQL 数据库采用了改良后的 B+树 结构,查找百万级的数据规模仅需最多遍历三层就能命中,将读取效率发挥到极致。
那什么是 Radix树呢?
首先,我们构造一个JSON数据集如下:
{
"do": 0,
"dog": 1,
"dax": 2,
"dogu": 3,
"dodo": 4,
"house": 5,
"houses": 6
}
如何高效地搜索一个字符串在数据集中所对应的最终值?我们可以构建一棵树来表示该数据集。Radix树 (Radix Trie)是利用树状结构对于搜索进行优化的树。
将这个数据集的键(例如 dog)和值(例如 0)按照 Radix 树状结构组织起来,就是图 4-2 所示的结构,
值存储于节点中,键的存储拆分开存在树的路径中。
当查找 dodo 的值时候,仅需要从根节点开始,向下遍历三层,依次找到 d-o-d-o 四个字母即可,它对应的值是 4 。
这棵树中间键无对应值的节点的存储空间里是 null 。
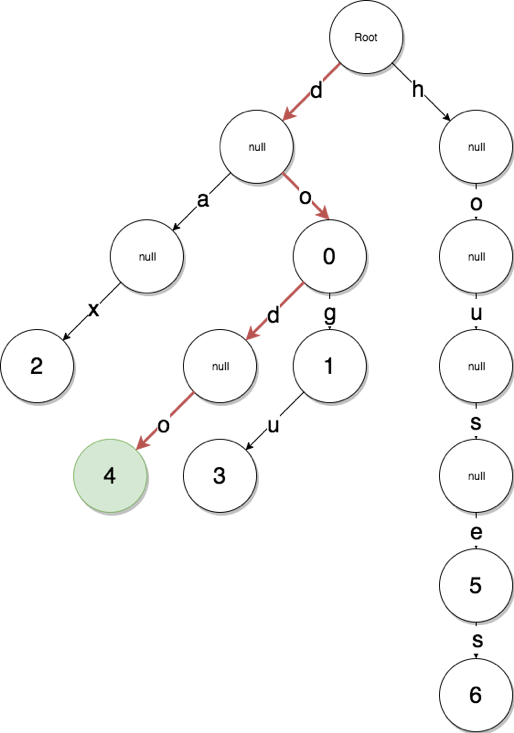
Radix Trie树存储简单的键值对数据集
如果我们仔细观察上述的树结构,发现右边有一个特别长的键链条 h-o-u-s-e-s ,它并不分叉,而是一条直线,从上到下连接节点。
这时候我们说树的性能产生了 “退化” ,变成了一维数组的遍历(性能从log2(N)变成了N)。
在遍历的路上,树中节点的值都是 null ,直到 e-s 位置才有了值 5 和 6 。
这不但是搜索效率的下降,从 log2(N) 退化到了 O(N),而且无值中间节点的堆积也是对存储空间的浪费。
所以我们对它进行改进,让有且仅有一个孩子节点的中间节点“合并路径”,这样搜索起来就快很多了,仅需两次向下搜索就可以找到 h-o-u-s-e-s,如图 4-3 所示。
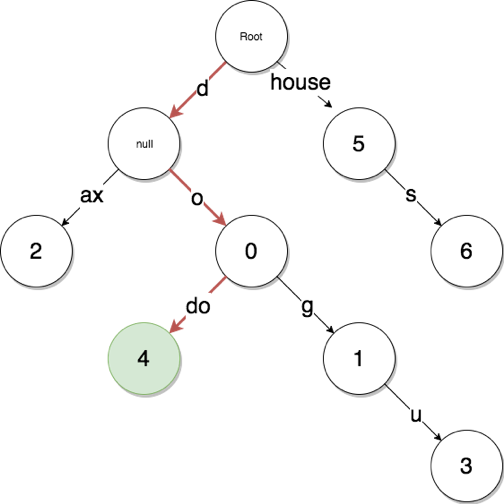
改进后的Radix树,house路径缩短
至此,Radix树已经介绍完毕。
| [1] | 笔者注:Trie和 Tree 是同音,在计算机学中特指带搜索性质的树状结构 |